Data Choreographics

Photo by Aram Boghosian










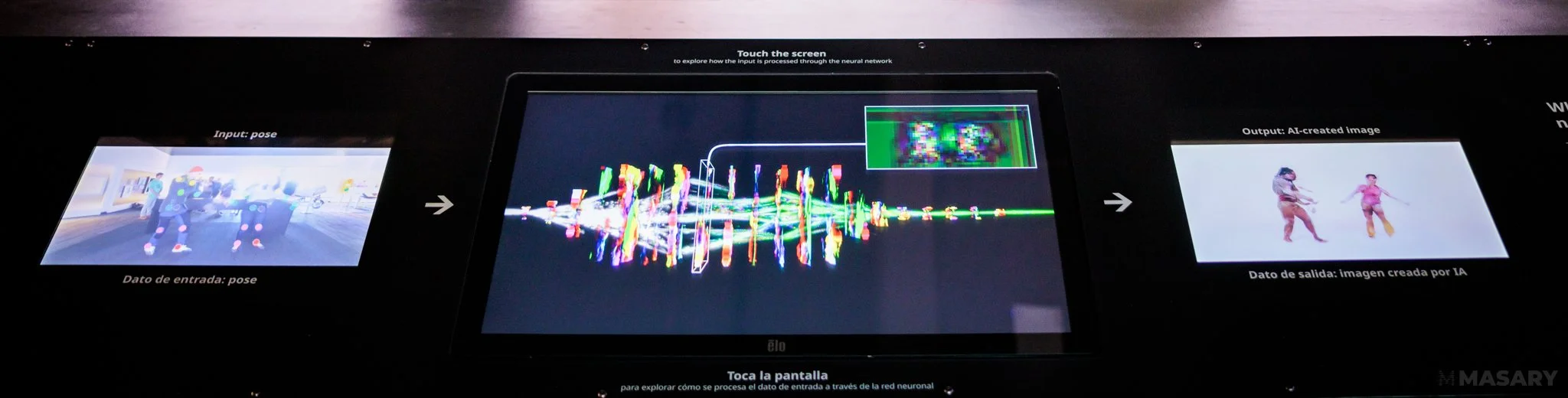
A still graphic of the aestheticized rendering of a neural network.
From left to right: Peter DiMuro/Public Displays of Motion - Modern Connections Collective - Evolve Dynamicz - Ellice Patterson, of Abilities Dance Boston - Eli Pabon's BOMBAntillana - StiggityStackz Worldwide
From top to bottom: Input Label - Real Image - Synthesized Image
DATA CHOREOGRAPHICS
Created by MASARY Studios
2022 - Museum of Science, Boston
Data Choreographics is an interactive artwork that explores contemporary artificial intelligence (AI) technologies through movement and dance. The artwork makes use of real-time pose estimation and Nvidia's pix2pixhd neural network architecture to transform the participant's image into images of professional dancers, while providing an interface to explore the inner workings of the neural network.
Data Choreographics premiered in September, 2022, at the Museum of Science, Boston as part of the Exploring AI: Making the Invisible Visible exhibit.
Commissioned by Museum of Science, Boston
FULL CREDIT & COLLABORATION LIST
Photos by Aram Boghosian
The Artwork
Data Choreographics invites museum-goers to interact with an image-generating neural network in two ways: through somatic exploration, on the one hand, and through deeper investigation and observation of the inner workings of the system, on the other.
Stepping in front of the primary video projection, a stereographic camera analyzes an individual's movement and pose using a state-of-the-art pose estimation algorithm (itself a neural network). The estimated pose is then fed into a generative neural network that has been trained on a custom sample corpus made up of images of professional dancers. This neural network transforms the individual's pose into a new image that resembles the captured footage of professional dancers. As one moves in front of the artwork, they are confronted by their own AI-generated mirror-image – an image that can rapidly transform in appearance, taking on shifting characteristics of many dancers.
Stepping behind the Data Choreographics console, museum-goers can observe a number of the inner workings of the artwork and software in real-time across three displays. On the left of the console, one can see the camera feed that is serving as the input into the artwork. This camera feed display also indicates the results of the pose estimation model, with colored dots overlaid on the bodies of individuals who are moving in front of the camera and video projection. Each dot indicates the location of a given joint on the body. The pose estimator attempts to find the location for each of 14 such "anchor" positions on each body: head, neck, and one for each shoulder, elbow, wrist, hip, knee, and ankle. The collection of 14 such anchor points per individual interacting with the artwork is used as the input into the generative neural network.
In the center of the console is an aestheticized rendering of the neural network. Data flows through the neural network from left to right, passing through a number of discrete layers, each made up of thousands or even millions of individual artificial neurons and each transforming the data in different ways. By touching the screen, one can select a given layer within the network for preview, displaying the output of the layer on-screen. Tracing the progress of the data through the network, it is possible to get a glimpse into the ways the network transforms the pose data into the final output image: resolution changes, becoming highly pixelated before rebuilding higher-resolution details, the dots produced by the pose estimator gradually disappear as the image transforms to contain more recognizable shapes and forms resembling human bodies.
On the right of the console, the final output image can be seen: the participant(s) transformed into the likeness of professional dancers using contemporary artificial intelligence technologies.
Creating the Artwork
The Sample Corpus
The core neural network in Data Choreographics is trained using a custom image corpus created for the artwork. This image set is the result of studio video shoots with six Boston- and Cambridge-area dance troupes. Each group was invited to contribute to the project and was asked to perform both pre-set and improvised movements that exemplify their own unique choreographic and performative voices. As such, the leader or choreographer of each group was encouraged to present and explore the choreographic ideas that they feel the greatest resonance with. While some direction was provided by the MASARY Studios creative team, we attempted to keep this direction primarily in regards to camera position and view, entrances and exits. Each group was also encouraged to present movement material using a variety of groupings and configurations – solos, duos, trios, etc. – as well as a variety of costumes that they perform in.
Over the course of video shoots with six dance groups–each recorded by three cameras at separate vantage points–we produced a vast dataset to draw from. Editing of the raw footage was performed primarily for the sake of ensuring effective sample creation and neural network training: video content where individuals were on the edge of the frame was cut as these segments were more likely to cause problems with the pose estimator, resulting in errors in training. Attempts were made to preserve as much footage as possible and the MASARY team did not edit any dance footage on the basis of aesthetics.
Once the video footage was edited, it was used to create the training set. A training set for a supervised or conditioned neural network like the one used for Data Choreographics requires both input samples and target samples as correlated pairs. For this project, the input samples are the pose estimator results and the target samples are the recorded images of the dancers.
In order to create the training set from the video footage, we first extracted each frame from the footage as discrete images. Then, every image was passed through a pose estimator to analyze the image and approximate the pose and bodily position of every person in each frame.
The result of this process is a unique training set consisting of approximately 3 million discrete samples (pose / image pairs). From this set, we produced a number of smaller subsets that were used to train a number of neural network models.
Training the Neural Network
Training the neural network used in Data Choreographics involved a number of steps. First, extensive testing and evaluation was performed on the network architecture to find the network settings (referred to as "hyperparameters" in machine learning parlance) that would offer the best balance between speed and image fidelity. Hyperparameters pertaining to network depth (number of layers) and breadth (number of learnable parameters in each layer) are the primary settings to tweak. Larger networks (those with greater numbers of learnable parameters) can potentially learn much more complex relationships between input and target output, but the size of the network in memory can quickly become impossible to use. For Data Choreographics, it was paramount that the neural network in the artwork be able to run as quickly as possible, allowing for real-time interaction and a highly responsive feel.
Once hyperparameters were set as desired, we trained a number of neural network models using our image set. Training involves showing the neural network input samples and evaluating its attempts to create the desired output. At each step, we compare the output from the neural network to the corresponding target sample (image of dancers) and score its performance (produce an error or "loss" signal). This signal is then used to adjust the parameters within the neural network a very small amount to lessen this error. During training, we repeat this process using all of the training samples many times. The network will be shown millions of samples and adjusted slightly after each. Over time and many iterations, the network learns to more accurately generate images as desired.
For Data Choreographics, we took several strategies for training the neural network. First, we trained separate models on footage from different dance troupes. This provides less variety in the training samples–instead of learning to generate images with the likeness of 20+ individuals, it's learning to generate images with the likeness of 1-6 dancers–which fits well with the reduced network size required for real-time application. We also trained several models on the entirety of the training set, resulting in less fine detail and much more abstract results.
Sound
The Data Choreographics sound score was developed to accompany and support the visual components of the piece while inspiring participants to move and dance. The sound score was created to encourage curiosity while not being overly referential to specific styles of music.
The sounds included in Data Choreographics were created using original samples generated by studio recording of unconventional percussion sounds, analog synthesizers and more. These sounds were used to compose a number of different "stems" (individual musical phrases, patterns, and layers) that are employed within an algorithmic combinatorial system to create a sound score that evolves, changes, and doesn't ever repeat in obvious or expected ways. The sound system responds to the presence of participants by activating multiple textures and patterns when people are in front of the artwork, fading these layers out when no one is actively moving in front of the piece. The number of participants corresponds to the density of rhythmic events and increased movement or motion in different areas drives timbral variation in several of the sound layers. By attaching data pertaining to the participants' engagement and movement within the artwork to various parameters related to sound levels, dynamics, activity and signal processing, the sound score welcomes individuals into an embodied experience with the artwork.